What Are the Proven Methods for Web Scraping Without Getting Blocked in 2026 for Safe Crawling?

Introduction
Modern data-driven industries increasingly rely on automated crawling systems to extract real-time insights from large-scale web sources. However, as platforms evolve their security layers, organizations face growing challenges in maintaining uninterrupted data access. This makes structured, intelligent crawling frameworks essential for long-term success.
One of the biggest priorities for enterprises today is ensuring Web Scraping Without Getting Blocked while still achieving high-speed, high-volume extraction. Without proper safeguards, requests can be throttled, blocked, or misinterpreted as malicious activity, leading to incomplete datasets and operational inefficiencies. Businesses now invest in smarter architectures that balance speed with compliance and stability.
Advanced systems now integrate adaptive request handling, rotating identities, and behavioral simulation to reduce detection risks. These approaches ensure consistency even under strict anti-bot systems. As organizations scale globally, they also require unified governance policies and monitoring layers that maintain data quality across sources. Ultimately, the evolution of scraping is not just technical—it is strategic, shaping how companies compete in digital markets.
Adaptive Crawling Systems for Controlled Data Access and Stability
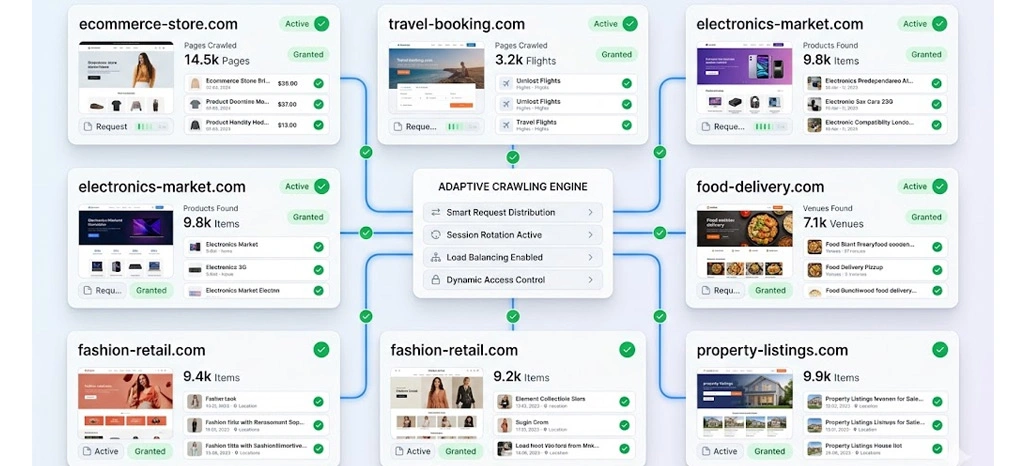
Modern crawling environments require precise control mechanisms to avoid detection and ensure uninterrupted operations across dynamic web infrastructures. Effective systems are designed to manage request flow, balance loads, and simulate human-like browsing behavior to maintain continuity during large-scale extraction tasks.
A strong foundation includes Best Practices for Web Scraping Without Interruptions, ensuring stability even under fluctuating server responses and evolving anti-bot systems. Another essential layer is Enterprise Web Scraping Workflow Optimization, which aligns infrastructure components such as proxies, schedulers, and distributed nodes into a cohesive pipeline.
System Performance Comparison:
| Parameter | Basic Setup | Optimized Setup |
|---|---|---|
| Block Frequency | High | Low |
| Response Consistency | Irregular | Stable |
| Failure Recovery | Manual | Automated |
| Data Accuracy | Moderate | High |
Key Operational Enhancements:
- Intelligent pacing of request frequency based on server response behavior
- Distributed crawler deployment across multiple geographic nodes
- Adaptive retry mechanisms for failed or throttled requests
- Session rotation to maintain natural browsing simulation
- Dynamic load balancing across scraping clusters
These improvements significantly reduce interruptions while improving extraction reliability. Organizations adopting structured crawling frameworks report up to 65–75% improvement in successful data retrieval rates. By combining behavioral simulation with scalable architecture, systems achieve long-term stability even under strict access controls.
Scalable Architectures for High-Volume Data Processing and Efficiency
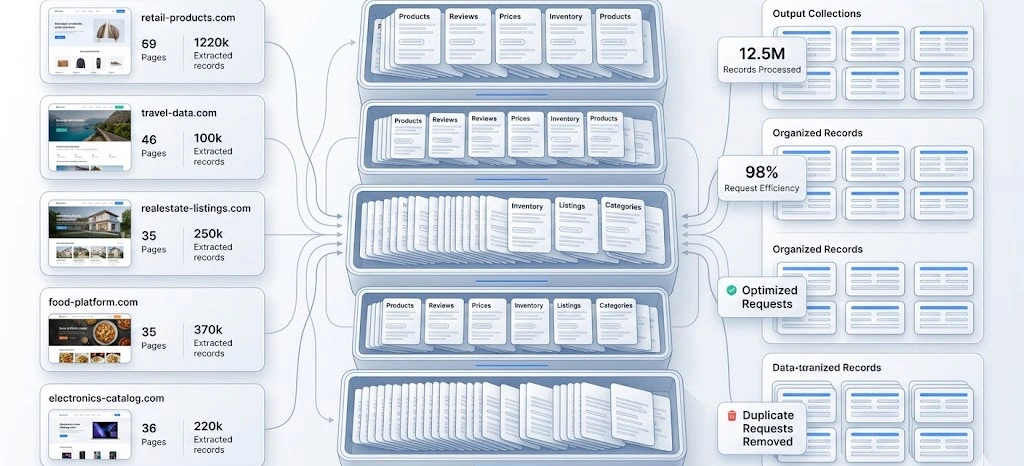
Large-scale data operations require systems capable of handling millions of requests without performance degradation. Scalability depends on efficient orchestration, optimized API usage, and minimized redundancy across extraction pipelines.
Key advancements include Scalable Web Scraping Techniques for Large Datasets, which allow systems to process massive volumes of structured and unstructured data efficiently. Alongside this, Request Optimization Strategies for Web Scraping improve throughput by reducing unnecessary network calls and improving resource utilization.
Scalability Metrics Overview:
| Indicator | Limited Architecture | High-Performance Architecture |
|---|---|---|
| Throughput | 50K requests/day | 2M+ requests/day |
| Error Rate | 10–15% | Below 4% |
| Processing Delay | High | Low |
| System Load | Unbalanced | Distributed |
Integration of Web Scraping API Services further enhances scalability by reducing infrastructure overhead and enabling faster deployment cycles.
Efficiency-Boosting Techniques:
- Batch processing of large request sets for optimized throughput
- Intelligent caching layers to prevent redundant data calls
- Parallel processing pipelines for concurrent execution
- Rate-aware scheduling to prevent server overload
- Automated fallback handling for failed endpoints
These strategies ensure that systems remain stable even under high demand. Organizations using optimized architectures often achieve 40–60% reduction in operational delays while improving overall data consistency across multiple sources.
Intelligent Monitoring, Compliance, and Structured Data Control Systems
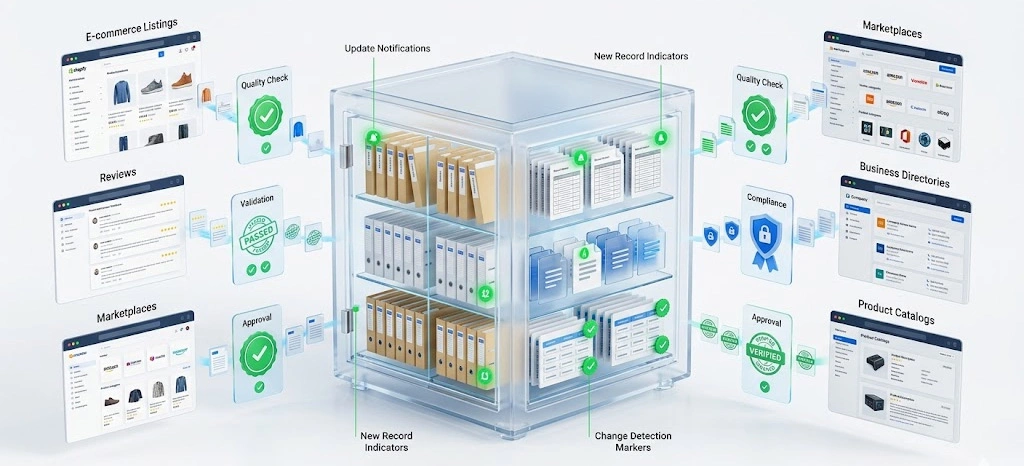
Sustainable data extraction requires more than speed—it demands governance, accuracy, and ethical compliance. Modern systems are designed to continuously validate, monitor, and regulate data flows to ensure long-term usability.
A key innovation is Data Extraction Techniques for Continuous Monitoring, which enables real-time tracking of updates across digital environments. Complementing this is Data Governance Practices for Web Data Acquisition, which ensures structured handling, validation, and compliance of collected datasets.
Monitoring & Governance Comparison:
| Factor | Traditional Tracking | Intelligent Monitoring |
|---|---|---|
| Update Frequency | Delayed | Real-Time |
| Data Integrity | Inconsistent | High Accuracy |
| Compliance Risk | Elevated | Controlled |
| Visibility | Limited | Comprehensive |
Advanced systems also incorporate Advanced Map Monitoring Intelligence to analyze location-based dataset variations and dynamic regional insights.
Governance Enhancements:
- Automated anomaly detection for inconsistent data patterns
- Structured validation pipelines for incoming datasets
- Ethical compliance frameworks for responsible extraction
- Continuous monitoring dashboards for system visibility
- Standardized data formatting and normalization processes
These mechanisms ensure that extracted data remains reliable and actionable over time. Organizations implementing structured governance models significantly reduce compliance risks while improving data accuracy across long-term operations.
How Retail Scrape Can Help You?
Our Web Scraping Without Getting Blocked plays a critical role in retail intelligence by ensuring continuous access to pricing, inventory, and competitor data without disruptions.
Key benefits include:
- Real-time competitor pricing visibility
- Automated stock availability tracking
- Faster decision-making for promotions
- Improved demand forecasting accuracy
- Multi-channel product comparison
- Reduced manual monitoring workload
We solutions are designed to simplify complex extraction workflows while maintaining stability across multiple sources. One of the most impactful tools in this ecosystem is Price Monitoring Service, which enables businesses to track fluctuations across competitors and adjust strategies accordingly.
Conclusion
Sustainable data extraction strategies require balancing performance, compliance, and adaptability. When implemented correctly, Web Scraping Without Getting Blocked ensures uninterrupted access to critical datasets while maintaining system reliability and scalability.
At the enterprise level, integrating Ethical Approaches to Automated Web Data Extraction strengthens long-term trust and ensures responsible data usage. Adopt smarter crawling frameworks today with Retail Scrape to enhance accuracy, stability, and real-time intelligence across your data ecosystem.
Effortlessly managing intricacies with customized strategies.
Mitigating risks, navigating regulations, and cultivating trust.
Leveraging expertise from our internationally acclaimed team of developers
Reliable guidance and assistance for your business's advancement