What Makes Large-Scale Web Scraping: Handling Missing Data Reduce Errors by 60% in Data Pipelines?

Introduction
Modern organizations rely on web data to support pricing intelligence, competitor monitoring, market research, and operational decision-making. However, collecting millions of records daily introduces a significant challenge: incomplete datasets. Missing values can emerge due to website structure changes, network interruptions, anti-bot mechanisms, server timeouts, or inconsistent content formatting. When these gaps go unnoticed, analytics models, forecasting systems, and business reports become less reliable.
Studies show that poor data quality can reduce analytical accuracy by up to 60%, creating inefficiencies across data-driven operations. An effective strategy for Web Scraping Data Validation ensures that every collected record meets predefined quality standards while minimizing manual intervention. Businesses that prioritize structured verification processes experience fewer reporting inconsistencies, better forecasting accuracy, and stronger confidence in operational insights.
The growing importance of Large-Scale Web Scraping: Handling Missing Data stems from its ability to improve dataset completeness, reduce processing failures, and strengthen overall data reliability. Organizations that address missing information proactively build more resilient data pipelines capable of supporting long-term analytics initiatives and business growth.
Establishing Strong Foundations for Reliable Data Collection
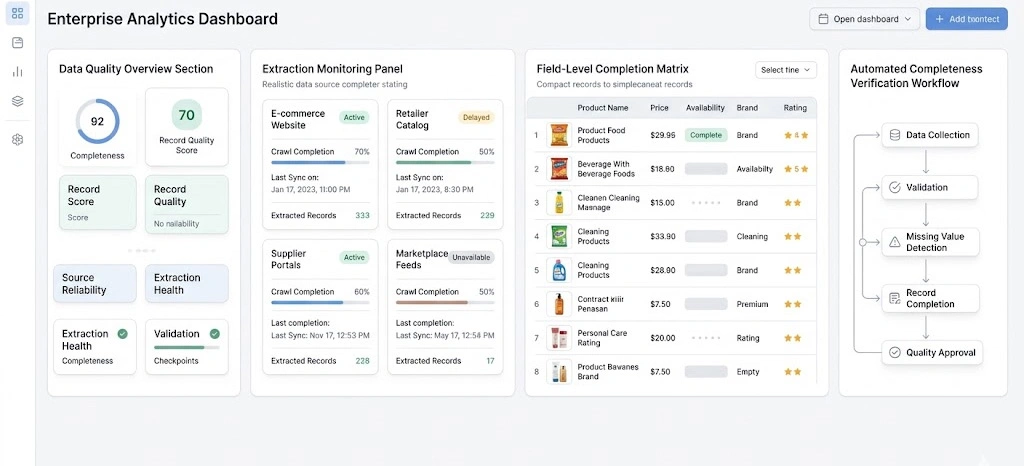
When web scraping operations scale across thousands of websites and millions of pages, maintaining dataset completeness becomes increasingly challenging. Even a small percentage of missing records can significantly impact reporting accuracy, forecasting reliability, and business intelligence initiatives. Data gaps often arise due to website redesigns, network interruptions, server-side restrictions, rendering issues, or inconsistent source structures.
Organizations increasingly implement structured monitoring systems to ensure extraction performance remains consistent over time. Real-time checks help identify anomalies before they affect analytical outputs, enabling teams to resolve issues proactively rather than reactively. Historical benchmarking is also valuable because it allows businesses to compare current collection trends against previous performance and quickly detect unusual fluctuations.
Many enterprises rely on Enterprise Web Crawling environments that provide visibility into extraction success rates, field-level completion, and source availability. Additionally, organizations focused on Handling Missing Data in Web Scraping benefit from automated completeness verification processes that continuously evaluate record quality throughout collection workflows.
| Data Integrity Challenge | Operational Impact | Recommended Solution |
|---|---|---|
| Layout Changes | Missing Fields | Schema Monitoring |
| Network Failures | Partial Records | Retry Mechanisms |
| Dynamic Content | Empty Values | Rendering Solutions |
| API Interruptions | Lost Data | Backup Collection |
| Crawl Errors | Dataset Gaps | Automated Alerts |
A well-structured quality framework supports Large-Scale Data Scraping initiatives by ensuring consistency across diverse sources and business units. These practices reduce operational risks while strengthening confidence in downstream analytics and reporting systems.
Implementing Automated Processes to Restore Data Accuracy
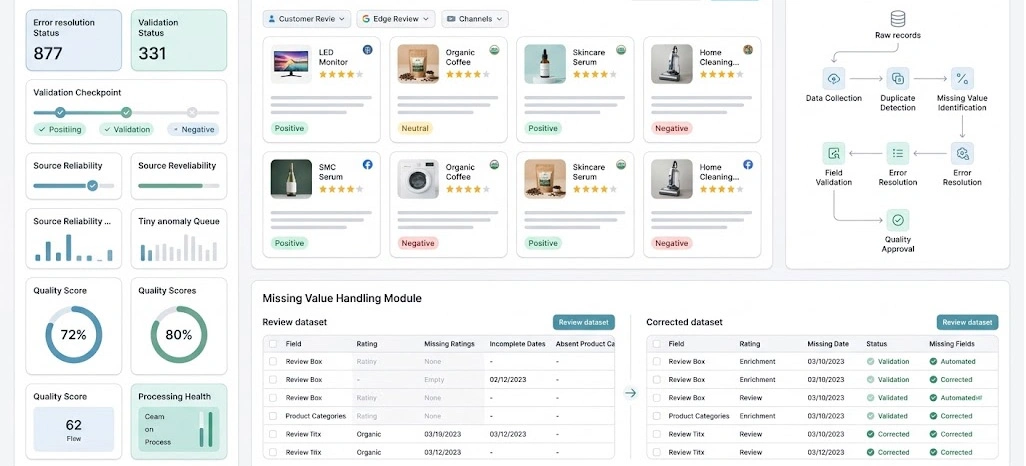
As scraping environments grow more complex, manual correction methods become increasingly ineffective. Organizations handling large-scale data operations require automated recovery frameworks capable of identifying, diagnosing, and correcting incomplete records without disrupting business processes. These systems help maintain dataset quality while significantly reducing operational overhead.
One of the most effective strategies involves continuous anomaly detection. Advanced monitoring tools evaluate incoming records against expected patterns and automatically flag inconsistencies. Businesses conducting Customer Sentiment Analysis depend heavily on complete and reliable datasets. Missing customer reviews, ratings, and feedback records can distort trend analysis and weaken strategic decision-making.
In addition, teams focused on Data Cleaning in Web Scraping frequently integrate validation checkpoints throughout collection pipelines. These checkpoints work alongside systems designed for Handling Missing Values in Scraped Data, ensuring that incomplete records are identified and corrected efficiently.
| Recovery Method | Primary Purpose | Expected Benefit |
|---|---|---|
| Retry Scheduling | Recover Failed Requests | Higher Success Rates |
| Historical Matching | Fill Missing Fields | Improved Completeness |
| Rule-Based Validation | Detect Anomalies | Better Accuracy |
| Automated Re-Crawling | Restore Lost Records | Reduced Gaps |
| Quality Audits | Verify Outputs | Consistent Data Standards |
An effective Web Scraping Error Handling strategy categorizes failures based on their root causes. Temporary network interruptions, source website modifications, and extraction logic issues each require different recovery approaches.
Creating Sustainable Frameworks for Long-Term Performance
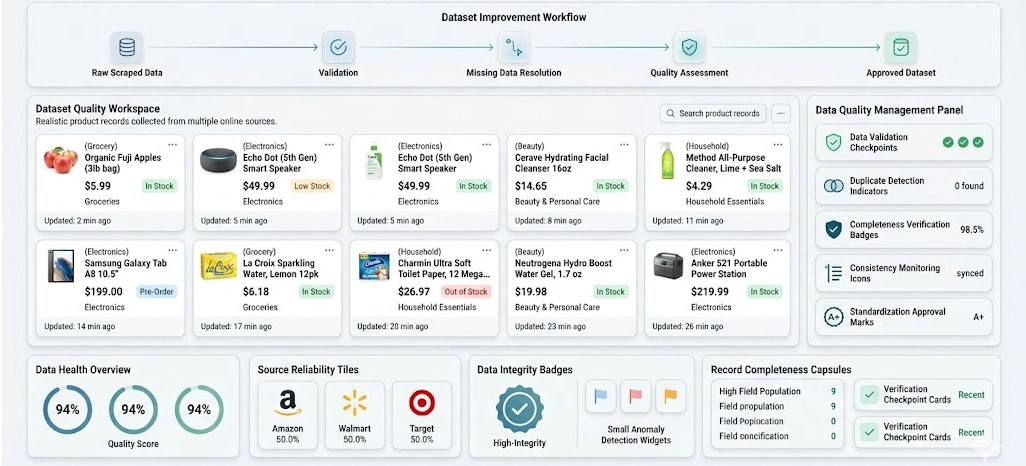
Maintaining reliable datasets requires more than periodic corrections. Organizations must establish long-term governance frameworks that continuously support quality, consistency, and operational efficiency. Retailers and consumer-focused businesses often rely on scraped datasets for inventory optimization, competitive monitoring, and Assortment Planning initiatives.
Successful organizations define measurable quality standards covering completeness, accuracy, consistency, and timeliness. Continuous monitoring further strengthens quality assurance efforts by delivering ongoing visibility into pipeline health. Organizations seeking How to Improve Scraped Dataset Quality frequently invest in automated auditing systems, governance policies, and proactive monitoring frameworks.
At the same time, Scraping Pipeline Optimization improves operational efficiency while minimizing the risk of incomplete records entering analytical workflows. Missing or inaccurate product information can affect purchasing decisions, demand forecasts, and category management strategies. Strong governance processes help ensure decision-makers receive complete and trustworthy information.
| Quality Framework Component | Purpose | Business Outcome |
|---|---|---|
| Performance Monitoring | Track Collection Health | Improved Visibility |
| Governance Standards | Define Quality Rules | Consistent Outputs |
| Automated Audits | Verify Data Integrity | Reduced Errors |
| Benchmark Tracking | Measure Improvements | Better Optimization |
| Continuous Enhancement | Adapt to Changes | Long-Term Reliability |
A structured approach to Data Quality Management for Scraping helps organizations maintain dependable datasets despite changing source environments. Through regular auditing, performance reviews, and automated monitoring, teams can identify weaknesses and implement corrective actions before data issues escalate.
How Retail Scrape Can Help You?
Reliable data collection requires more than simply gathering information from websites. By supporting Large-Scale Web Scraping: Handling Missing Data, our solutions help organizations reduce operational risks while maintaining dependable datasets for analytics and decision-making.
Our specialized services are designed to strengthen data reliability through:
- Continuous extraction monitoring
- Automated anomaly detection
- Intelligent recovery workflows
- Real-time quality reporting
- Multi-source collection management
- Scalable processing infrastructure
Retail Scrape combines advanced validation frameworks with a robust Web Scraping API that supports seamless integration into existing business systems. Through proactive monitoring and Missing Data in Scraping Projects mitigation strategies, organizations can maintain high-quality datasets while improving operational efficiency and analytical accuracy.
Conclusion
Incomplete datasets can undermine reporting accuracy, forecasting reliability, and strategic decision-making. Organizations that prioritize Large-Scale Web Scraping: Handling Missing Data create stronger foundations for scalable analytics while reducing costly pipeline failures and operational inefficiencies.
A proactive approach supported by monitoring, automation, and governance significantly improves data consistency over time. By focusing on Data Quality Management for Scraping, organizations position themselves for long-term success. Contact Retail Scrape today to build dependable data pipelines that support smarter business decisions.
Effortlessly managing intricacies with customized strategies.
Mitigating risks, navigating regulations, and cultivating trust.
Leveraging expertise from our internationally acclaimed team of developers
Reliable guidance and assistance for your business's advancement