What Can a Headless Browser vs API Comparison for Data Scraping Reveal About Performance Trends?

Introduction
Modern businesses rely on real-time web data to make informed decisions, monitor competitors, and optimize operations. As websites become increasingly dynamic and interactive, organizations face an important choice when building data collection workflows: whether to use browser-driven extraction methods or direct API access. Understanding the strengths and limitations of each approach is essential for selecting the most effective strategy.
A detailed Headless Browser vs API Comparison for Data Scraping helps businesses evaluate critical factors such as speed, scalability, infrastructure requirements, maintenance efforts, and extraction accuracy. While APIs often provide structured and efficient access to data, headless browsers can navigate complex web applications and capture content that may not be available through traditional endpoints.
Industry reports indicate that API-based collection methods can reduce extraction times by as much as 70% compared to browser-driven techniques in suitable environments. However, headless technologies continue to play a vital role where APIs are unavailable or limited. A comprehensive Web Scraping API vs Headless Browser assessment enables organizations to determine which approach aligns best with their operational goals.
Assessing Operational Efficiency Across Modern Data Collection Frameworks
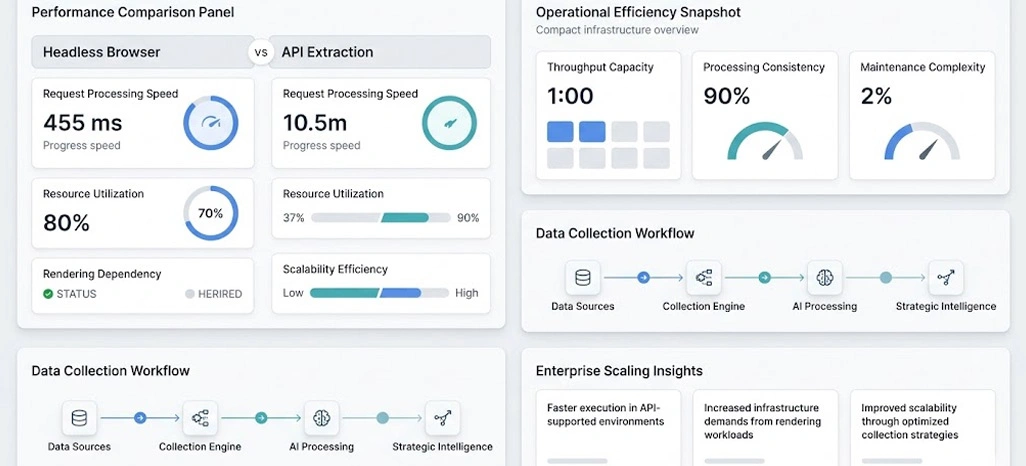
Performance is one of the primary considerations when selecting a web data extraction strategy. Organizations handling high-volume information streams require solutions that deliver speed, consistency, and cost efficiency. Browser-driven extraction methods typically load complete web pages, execute scripts, and render dynamic elements before collecting information.
Industry analysis indicates that API-driven approaches can process requests up to five times faster than rendering-based alternatives in suitable environments. Such differences become more noticeable when businesses expand data operations across multiple websites and regions. A detailed Headless Browser Performance Comparison helps organizations understand how rendering overhead impacts response times, resource utilization, and overall productivity.
Large organizations involved in Enterprise Web Scraping often prioritize performance because infrastructure expenses rise rapidly as extraction volumes increase. Choosing the appropriate collection method directly affects operational efficiency, maintenance requirements, and scalability.
| Performance Metric | Browser-Based Approach | API-Based Approach |
|---|---|---|
| Page Rendering Requirement | Yes | No |
| Processing Speed | Moderate | High |
| CPU Utilization | High | Low |
| Memory Consumption | High | Moderate |
| Scaling Capability | Moderate | Strong |
Organizations conducting Api-Based Scraping vs Browser Automation evaluations often identify substantial long-term savings through improved efficiency and reduced infrastructure demands. Understanding these operational dynamics enables businesses to develop extraction architectures that remain sustainable while supporting future growth and expanding analytical requirements.
Addressing Large-Scale Growth Requirements Through Flexible Architectures
As organizations increase their dependence on web intelligence, scalability becomes a critical factor in determining the effectiveness of extraction systems. A comprehensive Headless Browser Scraping Performance assessment highlights how browser-rendered workflows may encounter limitations due to session management complexities, rendering delays, and increased infrastructure requirements.
Modern analytics initiatives frequently depend on extensive Web Scraping Datasets to support forecasting, strategic planning, and market evaluation. These datasets require reliable collection mechanisms capable of processing large quantities of information across multiple platforms and digital environments.
When comparing Data Extraction API vs Browser Scraping, organizations often discover that APIs provide significant advantages for repetitive, high-volume requests due to their streamlined communication model. However, browser automation remains valuable when critical information is generated dynamically and cannot be accessed through direct endpoints.
| Scalability Factor | Browser Automation | API Access |
|---|---|---|
| Concurrent Processing | Moderate | High |
| Infrastructure Expense | Higher | Lower |
| Deployment Complexity | High | Moderate |
| Recovery Efficiency | Moderate | Strong |
| Throughput Capacity | Moderate | Very High |
Conducting a detailed Browser Automation Tools Comparison enables decision-makers to evaluate technologies based on performance expectations, operational goals, and future scalability requirements. By prioritizing adaptability from the beginning, organizations can build extraction ecosystems capable of supporting evolving business objectives while maintaining efficiency, reliability, and long-term sustainability.
Improving Consistency and Accuracy Within Dynamic Digital Ecosystems
Reliable information is the foundation of successful business intelligence initiatives. Inaccurate, delayed, or incomplete data can affect pricing decisions, operational planning, customer experience strategies, and market evaluations. For this reason, organizations must assess both accuracy and reliability when determining the most suitable extraction methodology.
Organizations evaluating Browser Automation vs Api-Based Scraping frequently determine that the most effective solution depends on the accessibility of target information and specific operational objectives. Browser automation can effectively capture interactive content, while APIs typically provide more structured and dependable outputs.
Applications involving pricing intelligence, inventory visibility, and Map Monitoring require dependable systems capable of adapting to frequent website modifications. Browser-rendered extraction approaches often provide deeper visibility into dynamic content, making them effective for collecting information that may not be directly exposed through structured endpoints.
| Reliability Criteria | Browser-Based Method | API-Based Method |
|---|---|---|
| Dynamic Content Accessibility | Excellent | Moderate |
| Structured Output Quality | Moderate | Excellent |
| Adaptability to Changes | High | Moderate |
| Error Detection Capability | Moderate | Strong |
| Data Consistency | Good | Excellent |
Similarly, businesses considering Api-Based Scraping Solutions often prioritize lower maintenance requirements and consistent data delivery. A thorough API Scraping vs Browser Automation Comparison demonstrates that combining both methodologies can create balanced workflows that maximize reliability, scalability, and extraction accuracy.
How Retail Scrape Can Help You?
Organizations seeking reliable web intelligence require solutions that balance speed, accuracy, and scalability. Through a comprehensive Headless Browser vs API Comparison for Data Scraping, we help businesses identify the most effective extraction strategy based on operational goals, target platforms, and data requirements.
Our expertise supports organizations through:
- Building scalable data collection frameworks
- Monitoring market trends across multiple channels
- Tracking pricing and inventory fluctuations
- Delivering structured datasets for analytics
- Supporting large-scale automation projects
- Enhancing data quality and validation processes
Businesses focused on Competitive Benchmarking can benefit from customized extraction solutions designed to provide actionable insights while minimizing operational complexity.
Our team also evaluates performance, infrastructure requirements, and implementation strategies using proven methodologies, including API Scraping vs Browser Automation Comparison, to help organizations maximize efficiency and long-term value from their data initiatives.
Conclusion
Organizations evaluating modern extraction technologies increasingly rely on a detailed Headless Browser vs API Comparison for Data Scraping to understand trade-offs related to speed, scalability, reliability, and infrastructure efficiency. Selecting the right approach depends on project requirements, data accessibility, and long-term operational objectives.
A thorough Headless Browser Performance Comparison enables businesses to make informed technology decisions that support sustainable growth and improved intelligence capabilities. Contact Retail Scrape today to build a customized data extraction strategy that delivers accurate, scalable, and business-ready insights.
Effortlessly managing intricacies with customized strategies.
Mitigating risks, navigating regulations, and cultivating trust.
Leveraging expertise from our internationally acclaimed team of developers
Reliable guidance and assistance for your business's advancement