How Can Enterprises Design Resilient Distributed Web Scraping Systems: Architecture Guide at Scale?

Introduction
As organizations increasingly depend on external digital data for strategic planning, pricing intelligence, market monitoring, and operational optimization, scalable web scraping has become a critical business function. Traditional single-server crawlers often struggle to process millions of pages efficiently while maintaining reliability, uptime, and data accuracy.
A distributed scraping framework enables organizations to divide crawling tasks across multiple nodes, allowing higher throughput and improved fault tolerance. Studies indicate that enterprises deploying distributed crawling infrastructures can improve extraction efficiency by over 60% while reducing downtime by nearly 45%. The growing demand for Parallel Web Scraping Services reflects the need for scalable solutions capable of managing high-volume extraction requirements.
Enterprises increasingly invest in architectures designed to process billions of data points while ensuring compliance, monitoring performance, and maintaining operational stability. This article explains how businesses can implement Distributed Web Scraping Systems: Architecture Guide principles to design reliable, scalable, and future-ready scraping ecosystems.
Establishing Efficient Workload Distribution Across Large-Scale Data Collection Networks
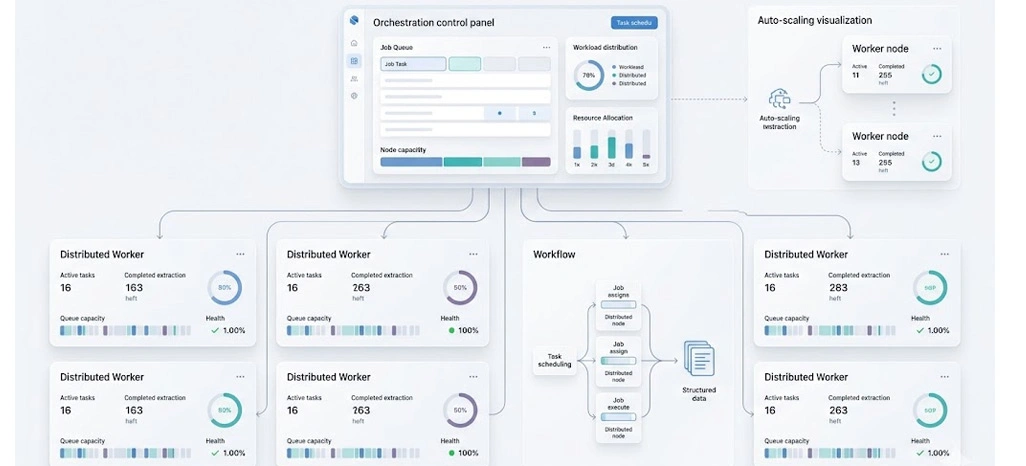
Managing millions of web requests across multiple sources requires a structured approach to workload allocation. When extraction activities are concentrated on a single server, organizations often face delays, processing bottlenecks, and higher failure rates. Research indicates that distributed task management frameworks can improve extraction throughput by more than 65% and reduce execution delays by nearly 40%.
Organizations aiming to Build Distributed Web Scraping Systems typically begin with centralized orchestration and decentralized execution. This setup allows task schedulers to assign jobs dynamically based on resource availability and crawler performance. As the volume of requests grows, scaling worker nodes becomes significantly easier than upgrading a single machine.
Modern businesses also rely on Web Scraping API Services to streamline request routing, authentication management, and data retrieval processes. These APIs simplify communication between extraction modules and reduce operational complexity. A well-designed Distributed Web Scraping Architecture ensures that workloads remain balanced while preventing duplicate requests and resource conflicts.
| Component | Purpose | Business Impact |
|---|---|---|
| Task Queue | Job allocation | Balanced processing |
| Scheduler | Priority management | Faster execution |
| Worker Nodes | Data extraction | Improved scalability |
| Retry Mechanism | Failure handling | Higher reliability |
| Resource Manager | Capacity control | Better utilization |
Furthermore, incorporating queue management systems improves reliability by prioritizing tasks and handling retries automatically. Enterprises that invest in intelligent workload distribution create a strong foundation for sustainable, large-scale data collection while maintaining operational efficiency and long-term scalability.
Strengthening Reliability Through Advanced Infrastructure and Recovery Frameworks
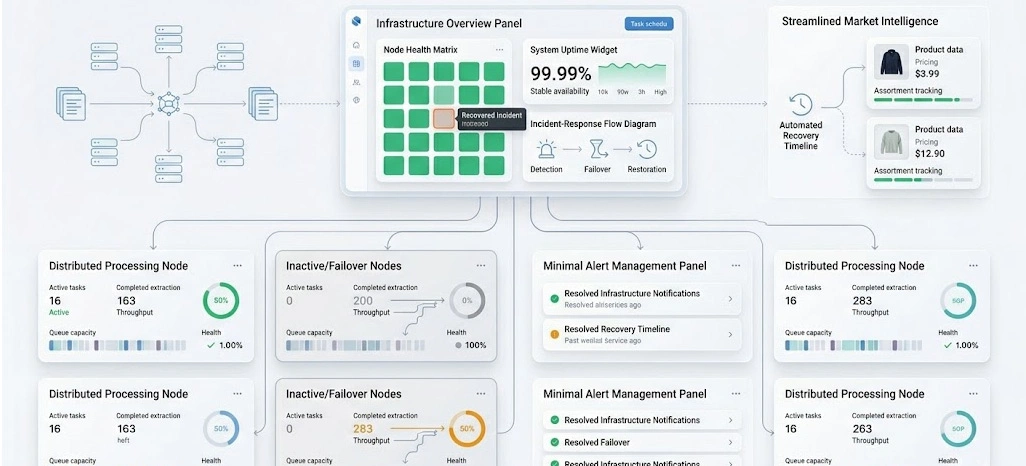
Large-scale web data extraction environments encounter numerous operational challenges, including network interruptions, website changes, server failures, and unexpected traffic surges. Without resilient infrastructure, these disruptions can negatively impact data quality and business intelligence initiatives. An effective Scraping Infrastructure Architecture focuses on redundancy, monitoring, and automated recovery capabilities.
Rather than depending on a single execution environment, enterprises deploy multiple processing nodes supported by load balancers and backup resources. For organizations conducting Competitor Analysis, uninterrupted access to market data is essential for monitoring pricing trends, promotional activities, and product assortment changes. Missing even a short period of data can impact strategic planning and forecasting accuracy.
Therefore, continuous monitoring systems play a crucial role in identifying failures before they affect operations. Many enterprises adopt Enterprise Web Scraping Solutions that integrate intelligent alerting systems, health checks, and automated failover mechanisms. These capabilities significantly improve operational resilience while minimizing manual intervention.
| Infrastructure Element | Function | Benefit |
|---|---|---|
| Load Balancer | Traffic distribution | Improved availability |
| Monitoring System | Issue detection | Faster response |
| Failover Cluster | Backup execution | Reduced downtime |
| Distributed Storage | Data redundancy | Greater protection |
| Logging Platform | Activity tracking | Easier diagnostics |
Additionally, a robust Scraping Pipeline Architecture separates collection, validation, transformation, and storage processes, ensuring that failures in one layer do not disrupt the entire workflow. By prioritizing reliability and recovery planning, organizations create stable environments capable of supporting continuous extraction activities despite changing operational conditions.
Enhancing Data Processing Performance for Enterprise Intelligence Workflows
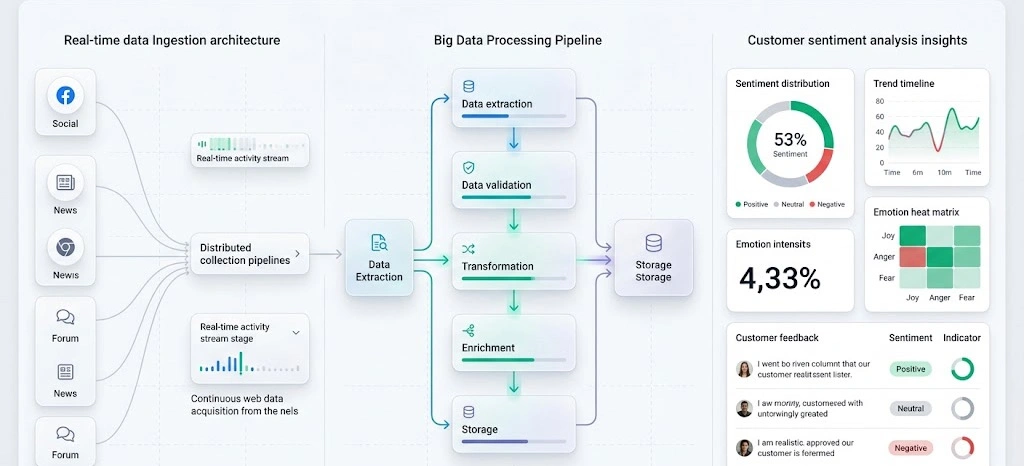
The true value of web extraction lies not only in collecting information but also in transforming it into actionable intelligence. As enterprises gather increasing volumes of structured and unstructured data, processing efficiency becomes a critical factor in determining business outcomes. Organizations implementing Real Time Data Scraping Systems can process incoming information continuously rather than waiting for scheduled batch updates.
This capability enables teams to react faster to market developments, inventory changes, and customer behavior trends. Continuous processing is especially valuable in dynamic industries where timely insights influence decision-making. Businesses conducting Customer Sentiment Analysis depend heavily on rapid processing pipelines that can transform large volumes of reviews, comments, and feedback into meaningful insights.
Delayed processing may reduce the relevance of collected information and limit strategic effectiveness. To support scalable operations, many enterprises adopt Real-Time Dataset Collection Architecture models that combine streaming technologies with distributed storage systems. These frameworks enable seamless movement of data across collection, validation, transformation, and analytics stages.
| Processing Stage | Objective | Business Value |
|---|---|---|
| Collection | Acquire information | Data availability |
| Validation | Verify accuracy | Reliable insights |
| Transformation | Standardize formats | Better usability |
| Storage | Preserve datasets | Long-term access |
| Analytics | Generate intelligence | Strategic decisions |
Furthermore, implementing Web Scraping Pipeline Architecture for Big Data ensures that massive datasets remain accessible, organized, and analysis-ready for various departments and business functions. A structured processing environment helps enterprises convert high-volume web data into meaningful intelligence while supporting growth, scalability, and faster decision-making across the organization.
How Retail Scrape Can Help You?
Managing enterprise-scale scraping operations requires specialized expertise, scalable infrastructure, and continuous monitoring capabilities. Businesses implementing Distributed Web Scraping Systems: Architecture Guide strategies need solutions that combine scalability, reliability, and performance.
Our capabilities include:
- Scalable multi-node crawling environments
- Intelligent task scheduling and orchestration
- Automated error detection and recovery
- High-volume data processing workflows
- Continuous monitoring and reporting
- Secure data storage and management
Through advanced Enterprise Web Crawling capabilities and Real-Time Dataset Collection Architecture methodologies, Retail Scrape helps organizations build resilient ecosystems that deliver accurate and actionable data at scale.
Conclusion
As data-driven decision-making becomes increasingly important, organizations must invest in resilient architectures capable of supporting large-scale extraction operations. Implementing the principles outlined in Distributed Web Scraping Systems: Architecture Guide enables enterprises to improve reliability, scalability, and operational efficiency while supporting long-term growth objectives.
A robust Scraping Infrastructure Architecture ensures continuous performance even under demanding workloads. Contact Retail Scrape today to build a scalable web scraping ecosystem that transforms large-scale data collection into measurable business intelligence and competitive advantage.
Effortlessly managing intricacies with customized strategies.
Mitigating risks, navigating regulations, and cultivating trust.
Leveraging expertise from our internationally acclaimed team of developers
Reliable guidance and assistance for your business's advancement