How Do 5 Technical Hurdles Affect 80% Accuracy in Amazon Data Scraping Challenges and Solutions?

Introduction
In today’s hyper-competitive eCommerce ecosystem, accurate marketplace intelligence determines pricing power, assortment planning, and revenue growth. However, extracting large-scale product and pricing information from Amazon is far from simple. Businesses often assume scraping is a straightforward automation task, yet nearly 80% of data collection initiatives experience quality or continuity issues due to technical barriers, structural changes, and anti-bot mechanisms.
From IP blocking and CAPTCHA triggers to dynamic JavaScript rendering and inconsistent product variations, companies encounter recurring roadblocks that directly impact data accuracy. These obstacles reduce confidence in dashboards, distort competitor benchmarking, and weaken pricing strategies. That is why understanding Amazon Data Scraping Challenges and Solutions is critical before deploying large-scale extraction systems.
Modern enterprises are shifting toward structured Amazon Product Data Scraping Solutions that combine automation, proxy rotation, and adaptive parsing logic to maintain consistency. With the right technical framework, businesses can minimize disruptions and significantly improve data reliability.
This blog explains five major technical hurdles affecting scraping accuracy, supported by statistics, structured comparisons, and practical remedies that help organizations achieve scalable and compliant data collection.
Overcoming Blocking Mechanisms and Access Restrictions at Scale

Anti-bot systems remain one of the most disruptive barriers to large-scale marketplace data collection. Nearly 65% of extraction failures occur due to IP bans, CAPTCHA challenges, or request throttling. These interruptions create incomplete datasets, delay reporting cycles, and distort competitive benchmarking models. Businesses attempting automation without a structured Amazon Web Scraping Challenges Guide often encounter repeated block patterns that reduce operational efficiency.
A deeper look into Amazon Data Extraction Challenges shows that seller-level tracking, Buy Box monitoring, and regional price capture are especially vulnerable to access restrictions. Teams focused on Scraping Amazon Data Without Blocks must implement intelligent proxy rotation, browser fingerprint management, and dynamic header configuration. Without these layers, scraping accuracy frequently drops below 60%.
Technical teams also rely on an Amazon Anti-Scraping Protection Bypass Guide to design adaptive request intervals and behavior-based browsing simulation. For businesses requiring stable and compliant integrations, the Amazon Product & Price Data API provides structured access while minimizing exposure to blocking triggers.
| Challenge Type | Impact on Dataset | Approx. Failure Rate | Technical Resolution |
|---|---|---|---|
| IP Blocking | Interrupted sessions | 40% | Residential proxy rotation |
| CAPTCHA Validation | Partial product extraction | 25% | Behavior simulation engines |
| Rate Limiting | Missing SKU refresh | 18% | Smart throttling algorithms |
| Geo Restrictions | Regional pricing gaps | 12% | Geo-targeted IP pools |
Addressing these layers systematically improves extraction continuity and restores data completeness to above 85%, ensuring consistent competitive insights.
Managing Structural Changes and Dynamic Page Rendering Complexities
Frequent layout updates and JavaScript-driven rendering environments create persistent instability in scraping frameworks. Studies indicate that 30–35% of automation scripts fail within three months due to HTML structure modifications. These evolving page elements are central to broader Amazon Web Scraping Difficulties, particularly when static selectors are used without adaptive logic.
Implementing the Best Way to Scrape Amazon Product Data requires headless browsers, automated DOM comparison tools, and AI-assisted selector regeneration. Without these capabilities, data gaps in variant listings, sponsored placements, and nested product attributes can reduce reliability by nearly 25%.
Modern extraction systems such as Smart Amazon Data Scraper are designed to detect layout changes automatically and recalibrate parsing logic in real time. This reduces downtime and maintains structured product mapping. Automated script testing pipelines further strengthen performance by validating extraction models before deployment.
| Structural Issue | Root Cause | Data Accuracy Loss | Mitigation Approach |
|---|---|---|---|
| Dynamic Content Loading | JavaScript rendering | 22% | Headless browser automation |
| DOM Restructuring | Layout updates | 28% | AI-based selector updates |
| Variant Nesting | Multi-level SKU mapping | 18% | Structured JSON parsing |
| Sponsored Blending | Mixed content injection | 12% | Content filtering logic |
Organizations that proactively monitor layout changes and implement adaptive parsing significantly reduce script failure rates and protect long-term data stability.
Resolving Data Inconsistencies and Quality Control Gaps
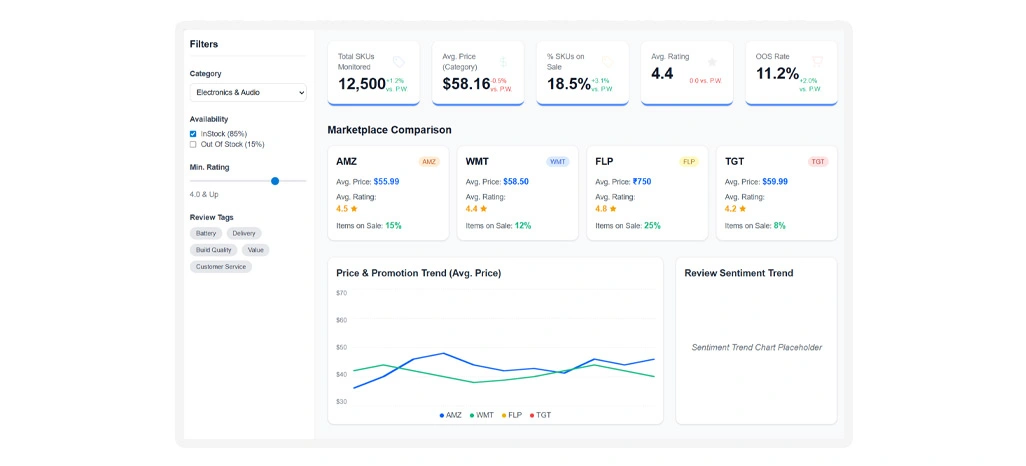
Even when access and structural barriers are controlled, dataset reliability can suffer from duplication, missing attributes, and inconsistent variant mapping. Research shows that nearly 45% of large marketplace datasets contain errors that impact pricing intelligence and assortment analysis.
Operational teams addressing How to Fix Amazon Scraping Issues must integrate validation layers directly after extraction. Deduplication algorithms, parent-child ASIN linking, and attribute normalization are essential for preventing analytical distortions. Instead of manually cleaning fragmented outputs, many enterprises rely on Ready-To-Use Amazon Product Datasets to ensure structured formatting and standardized fields.
Poor refresh scheduling also leads to outdated pricing snapshots, directly influencing repricing strategies and demand forecasts. Automated monitoring dashboards help detect anomalies and enforce scheduled updates.
| Data Quality Concern | Estimated Frequency | Business Impact | Corrective Method |
|---|---|---|---|
| Duplicate Listings | 20% | Pricing distortion | Deduplication logic |
| Missing Attributes | 15% | Incomplete reporting | Attribute enrichment |
| Variant Mismatch | 18% | SKU misalignment | Parent-child mapping |
| Stale Pricing | 12% | Faulty forecasting | Automated refresh cycles |
By embedding validation, enrichment, and anomaly detection mechanisms into extraction pipelines, businesses can improve accuracy from 70% to above 90%, ensuring reliable decision-making and long-term scalability.
How Retail Scrape Can Help You?
Accurate marketplace intelligence requires more than automation scripts. Addressing Amazon Data Scraping Challenges and Solutions demands a structured, scalable framework designed for reliability and compliance.
We provide enterprise-grade infrastructure to ensure consistent extraction and validation. Our technical ecosystem reduces disruption risks while improving dataset completeness.
Our Capabilities Include:
- Advanced proxy rotation and intelligent request pacing.
- AI-driven parsing systems adaptable to layout changes.
- Automated CAPTCHA handling workflows.
- Variant-level SKU normalization and enrichment.
- Real-time monitoring dashboards for error detection.
- Scheduled refresh mechanisms for pricing stability.
With our experience managing Amazon Web Scraping Limitations & Fixes, businesses achieve higher precision rates without operational bottlenecks. Our solutions are designed to support competitive pricing strategies, seller monitoring, and catalog intelligence at scale.
Conclusion
Technical barriers, structural instability, and inconsistent product attributes significantly impact scraping accuracy. Addressing these systematically improves extraction reliability and strengthens strategic decision-making. Businesses investing in structured Amazon Data Scraping Challenges and Solutions frameworks experience higher data stability and long-term performance gains.
By following insights from an Amazon Web Scraping Challenges Guide, organizations can transition from unstable scripts to enterprise-ready intelligence systems. Ready to transform your marketplace data accuracy? Connect with Retail Scrape today and build a smarter, more resilient data strategy.
Effortlessly managing intricacies with customized strategies.
Mitigating risks, navigating regulations, and cultivating trust.
Leveraging expertise from our internationally acclaimed team of developers
Reliable guidance and assistance for your business's advancement